Оглавление
3. Правила против стабильности
4. Использование подтипов и супертипов
5. Подтипы и супертипы как классы сущностей
6. Условные обозначения для построения диаграмм
7. Использование инструментов, которые не поддерживают подтипы
9. Атрибуты супертипов и подтипов
10. Неперекрывающийся и исчерпывающий
11. Перекрывающиеся подтипы и роли
11.1 Игнорирование совпадений в реальном мире
11.2 Моделирование только супертипа
11.3 Моделирование ролей как участия в отношениях
11.4 Использование классов сущностей ролей и взаимно однозначных отношений
13. Преимущества использования подтипов и супертипов
13.2 Презентация: Уровень детализации
13.4Вклад в разработку представлений
13.5 Классификация общих закономерностей
14. Когда мы прекратим супертипирование и подтипирование?
14.1 Различия в идентификаторах
14.2 Различные группы атрибутов
14.5 Миграция из одного подтипа в другой
14.7 Улавливание Смысла и Правил
15.1 Обобщение нескольких отношений «один ко многим» на одно отношение «многие ко многим»
15.2 Обобщение нескольких отношений «один ко многим» на одно отношение «один ко многим»
15.3 Обобщение отношений «Один ко многим» и «Многие ко многим»
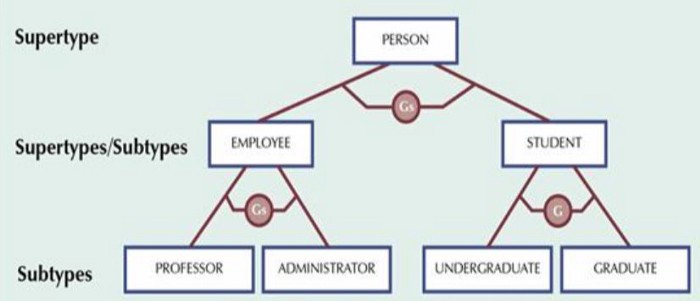
Подтипы сущностей вводятся в модель ER для того, чтобы уменьшить общее количество атрибутов каждой сущности.
Каждая сущность имеет набор уникальных атрибутов. Однако атрибуты разных объектов могут повторяться. Поэтому необходимо разработать ER-модель так, чтобы количество повторяющихся атрибутов в разных сущностях было минимальным или сводилось к нулю. Повторяющиеся атрибуты несут избыточность в базе данных. Размер базы данных становится неоправданно большим, поэтому эту проблему необходимо исправить. Для решения этой проблемы используются подтипы сущностей.
Идея использования подтипа сущности заключается в том, что для всего разнообразного набора сущностей выделяется супертип, который содержит информацию, общую для всех типов сущностей. Детали (тонкости) каждого типа сущностей вынесены отдельно в несколько специализированных подтипов.
Важно признать, что наш выбор уровня обобщения окажет глубокое влияние не только на базу данных, но и на дизайн всей системы. Наиболее очевидным эффектом обобщения является сокращение числа классов сущностей и, на первый взгляд, упрощение модели. Иногда это приводит к значительному снижению сложности системы за счет объединения общей программной логики. В других случаях увеличение сложности программы за счет объединения логики, необходимой для обработки совершенно разных подтипов, перевешивает выигрыш. Нужно особенно учитывать эту вторую возможность, если используете алгоритм для оценки размера и стоимости системы (например, в терминах функциональных точек). Более низкая оценка затрат, достигаемая за счет преднамеренного сокращения количества классов сущностей путем обобщения, может недостаточно учитывать связанную с этим сложность программирования.
Чтобы выбрать наиболее подходящий уровень обобщения, начинаем с рассмотрения важного различия между моделями: количества и типа бизнес-правил (ограничений), которые поддерживает каждая из них.
Модели, разработанные неопытными разработчиками моделей, часто включают слишком много правил в структуры данных, в первую очередь потому, что знакомые концепции и общие бизнес-термины сами по себе могут быть недостаточно общими. И наоборот, как только обнаруживается сила обобщения, появляется тенденция переусердствовать. Очень общие модели могут казаться практически невосприимчивыми к критике на том основании, что они могут вместить практически все. Это не блестящее моделирование, а отказ от проектирования в пользу разработчика моделирования процессов или пользователя, которому теперь придется подбирать все бизнес-правила, пропущенные разработчиком моделирования данных.
Неудивительно, что многие аргументы, возникающие при моделировании данных, касаются соответствующего уровня обобщения, хотя они не всегда признаются таковыми. Нельзя легко разрешить такие споры, обратившись к своду правил, не нужно отбрасывать интересные варианты слишком рано в процессе моделирования.
Способность представлять различные уровни обобщения требует нового соглашения о построении диаграмм — «коробка в коробке». Нужно быть очень осторожны с чрезмерным усложнением диаграмм со слишком большим количеством разных символов, но это буквально добавляет еще одно измерение (обобщение / специализация) к моделям.
Большая часть путаницы, которая окружает правильное использование подтипов и супертипов, может быть устранена с помощью простого правила: подтипы и супертипы являются классами сущностей.
- Используется одно и то же соглашение о построении диаграмм (прямоугольник со скругленными углами) для представления всех классов сущностей, независимо от того, являются ли они подтипами или супертипами некоторых других классов сущностей.
- Подтипы и супертипы должны поддерживаться определениями.
- Подтипы и супертипы могут иметь атрибуты. Атрибуты, характерные для отдельных подтипов, присваиваются этим подтипам; общие атрибуты присваиваются супертипу.
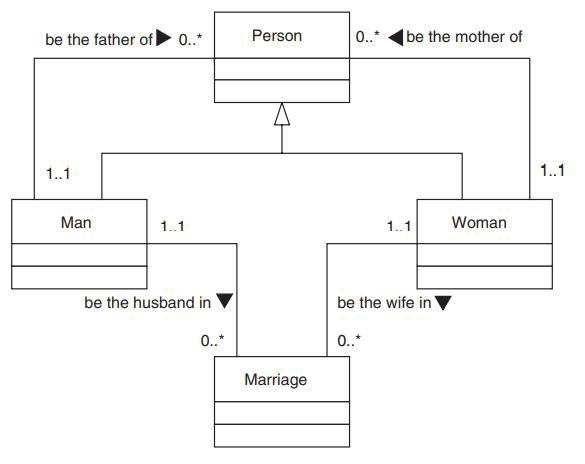
- Подтипы и супертипы могут участвовать в отношениях. Модель генеалогического древа, как аккуратно можно зафиксировать отношения “мать” и “отец”, привязав их к классам сущностей на наиболее подходящем уровне. Фактически, на этой диаграмме показано большинство видов связей, которые, по-видимому, беспокоят разработчиков моделей, в частности, связь между классом сущностей и его собственным супертипом.
- Подтипы сами по себе могут иметь подтипы. Не нужно ограничиваться двумя уровнями подтипов. На практике нужно представлять большинство концепций на одном, двух или трех уровнях общности, хотя время от времени полезно использовать четыре или пять уровней.
6. Условные обозначения для построения диаграмм
Коробки в Коробках
Используем соглашение “box-in-box” для представления подтипов. Это не единственный вариант, но он компактен, широко используется и поддерживается несколькими популярными инструментами документирования. Практически все альтернативные соглашения, включая UML, основаны на линиях между супертипами и подтипами.
В нотации UML подтипы представлены блоками снаружи, а не внутри блока супертипов.
7. Использование инструментов, которые не поддерживают подтипы
Некоторые инструменты документации вообще не предоставляют отдельного соглашения для подтипов, и обычно предлагается, чтобы они отображались как отношения «один к одному». Это довольно плохой вариант, но лучше, чем вообще игнорировать подтипы. Рекомендуется использовать имя отношения, такое как “быть” или “есть”, которое зарезервировано исключительно для подтипов.
Класс сущностей наследует определение своего супертипа. Таким образом, при написании определения подтипа задача состоит в том, чтобы указать, что отличает его от родственных подтипов (т.е. подтипов на том же уровне и, при необходимости, в пределах того же раздела).
9. Атрибуты супертипов и подтипов
Иногда можно придать модели смысл, представляя атрибуты на двух или более уровнях обобщения.
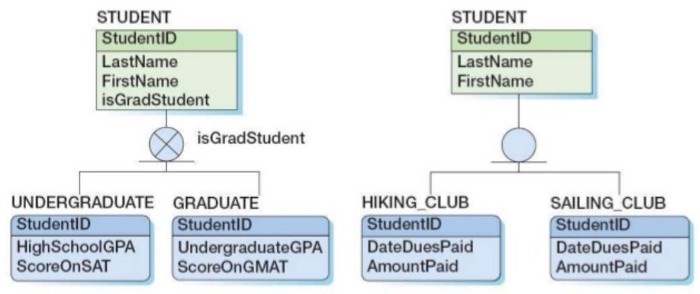
10. Неперекрывающийся и исчерпывающий
Подтипы в модели генеалогического древа подчинялись двум важным правилам:
- Они не перекрывали друг друга: данный человек не может быть одновременно мужчиной и женщиной.
- Они были исчерпывающими: данный человек должен быть либо мужчиной, либо женщиной, и ничем другим.
Фактически, эти два правила необходимы для того, чтобы каждый уровень обобщения сам по себе был допустимым вариантом реализации. Рассмотрим модель, в которой торговый партнер подразделяется на покупателя и продавца.
11. Перекрывающиеся подтипы и роли
Установив правило, согласно которому подтипы не должны перекрываться, остается проблема обработки определенных концепций и ограничений реального мира, которые, по-видимому, требуют перекрывающихся подтипов для моделирования. Наиболее распространенными примерами являются различные роли, которые играют люди и организации.
Многие из наиболее важных терминов, используемых в бизнесе (Клиент, Сотрудник, акционер, менеджер и т. Д.), То, как моделировать (и, следовательно, внедряем) эти роли, может иметь важные последствия для способности организации обслуживать своих клиентов, управлять рисками и соблюдать антимонопольное законодательство и законодательство о конфиденциальности. Есть несколько тактик, которые можно использовать, не нарушая правила “никаких совпадений”.
11.1 Игнорирование совпадений в реальном мире
Иногда можно моделировать так, как если бы определенных совпадений не существовало. Ранее проводились различие между правилами реального мира (“У каждого человека должна быть мать”) и правилами, касающимися данных, которые нам нужно хранить или которые мы можем хранить в реальном мире (“Мы знаем только матерей некоторых людей”).
11.2 Моделирование только супертипа
Одним из наиболее распространенных подходов к моделированию ролей людей и организаций является использование только одного класса сущностей супертипа для представления всех возможных ролей. Если подтипы вообще делаются, то на основе какого-либо другого критерия, такого как «тип класса юридического лица», партнерство, компания, физическое лицо и т.д.
11.3 Моделирование ролей как участия в отношениях
В модели только для супертипов, описанной выше, роли часто можно описать в терминах участия в отношениях.
Если не использовать нотацию Chen, то вместо того, чтобы еще больше усложнять нотацию отношений ради одного раздела модели, можно документировать такие правила в определении основного класса сущностей.
11.4 Использование классов сущностей ролей и взаимно однозначных отношений
Несмотря на эту неэлегантность в различении отношений от подтипов, подход к классу сущностей ролей обычно является наиболее точным решением проблемы, когда существуют значительные различия в атрибутах и отношениях, применимых к разным ролям.
Несколько инструментов CASE поддерживают частичное решение перекрывающихся подтипов, позволяя несколько разбивок (разделов) на полные, неперекрывающиеся подтипы.
Функция множественного разделения менее полезна при решении проблемы ролей, поскольку в итоге мы можем получить менее элегантное разделение.
У каждого подтипа может быть только один непосредственный супертип (в иерархии у каждого есть только один непосредственный начальник, кроме человека наверху, у которого его нет). Это следует из требования “не пересекаться”, поскольку два супертипа, содержащие общий подтип, будут перекрываться.
Немногие соглашения или инструменты поддерживают несколько супертипов для класса сущностей, возможно, потому, что они вводят сложность “множественного наследования”, при которой подтип наследует атрибуты и отношения непосредственно от двух или более супертипов.
13. Преимущества использования подтипов и супертипов
Каждый уровень в иерархии каждого подтипа представляет определенный вариант реализации бизнес-концепций, охватываемых супертипом самого высокого уровня. Но подтипы и супертипы предлагают преимущества не только в представлении вариантов, но и в поддержке творчества и решении сложных задач.
До сих пор использовались подтипы в творческом процессе немного пассивно. Две или более альтернативных моделей уже разработаны, и использованы подтипы для их сравнения на одной и той же диаграмме. Это очень полезная техника, когда разные разработчики моделей работают над одной и той же проблемой и (как это почти всегда бывает) создают разные модели.
13.2 Презентация: Уровень детализации
Подтипы и супертипы обеспечивают механизм представления моделей данных на разных уровнях детализации. Эта способность может иметь огромное значение для нашей способности общаться и проверять сложную модель. Если вы знакомы с методами моделирования процессов, вы будете знать ценность выровненных диаграмм потоков данных для представления сначала «общей картины», а затем деталей по мере необходимости.
Инструменты документирования, которые могут отображать и / или печатать несколько представлений одной и той же модели путем выборочного удаления классов сущностей и / или связей, полезны в такого рода деятельности.
Общение — это не только вопрос решения сложных задач. Терминология также часто является проблемой. Менеджер по транспортным средствам может интересоваться грузовиками, но бухгалтера интересуют активы. Наше соглашение о подтипировании позволяет представлять грузовик как подтип актива, поэтому оба термина отображаются в модели, и их взаимосвязь понятна.
При использовании подтипов и супертипов для передачи модели нам не нужно иметь намерения реализовывать их в виде таблиц; коммуникация сама по себе является достаточно веской причиной для их включения.
13.4Вклад в разработку представлений
Взглянув на это с другой стороны, использование подтипов и супертипов для отражения различных точек зрения на данные дает нам ценный вклад в спецификацию полезных представлений и поощряет строгость в их определении.
13.5 Классификация общих закономерностей
Можно использовать супертипы, чтобы помочь классифицировать и распознавать общие закономерности.
Структурированный подход к моделированию дает нам возможность атаковать модель сверху вниз, посередине или снизу вверх.
С точки зрения творческого моделирования, нисходящий подход, основанный на специализации, позволяет нам внедрить набор ключевых концепций на уровне супертипа и вписать остальные наши результаты в эту структуру. Здесь есть хорошая аналогия с архитектурой: основная форма здания определяет, как будут удовлетворены другие потребности.
14. Когда прекратится супертипирование и подтипирование?
Ни одно правило не говорит, когда прекратить создание подтипов, потому что используем подтипы для нескольких разных целей. Можно, например, показать подтипы, которые не намерены реализовывать в виде таблиц, чтобы лучше объяснить модель. Вместо этого есть несколько рекомендаций. На практике можно обнаружть, что они редко конфликтуют.
14.1 Различия в идентификаторах
Если класс сущностей может быть разделен на классы сущностей, экземпляры которых идентифицируются по разным атрибутам.
14.2 Различные группы атрибутов
Если класс сущностей может быть подразделен на классы сущностей, которые имеют разные атрибуты, рассмотрите возможность отображения подтипов.
Если класс сущностей можно разделить на подтипы таким образом, что один подтип может участвовать в отношениях, в то время как другой никогда не участвует, покажите подтип.
Если некоторые экземпляры класса сущностей участвуют в важных процессах, в то время как другие этого не делают, рассмотрите возможность создания подтипов. И наоборот, классы сущностей, участвующие в одном и том же процессе, являются кандидатами на супертипирование.
14.5 Миграция из одного подтипа в другой
Если реализовать базу данных, основанную на таких нестабильных подтипах, нужно передавать данные из таблицы в таблицу каждый раз, когда статус меняется. Это усложнило бы обработку и затруднило бы отслеживание экземпляров сущностей с течением времени.
Иногда полезно показать только два или три иллюстративных подтипа. Чтобы избежать нарушения правила полноты, нужно добавить класс сущностей “разное”.
14.7 Улавливание Смысла и Правил
Часто предоставляется информация, которую удобно представить в концептуальной модели данных, даже если не планируется включать ее в конечную (одноуровневую) логическую модель. Например, специалист по бизнесу может сказать: “Только управленческий персонал может брать кредиты для персонала”.
Подтипы и супертипы — это инструменты, которые используются в процессе моделирования данных, а не структуры, которые появляются в логических и физических моделях, по крайней мере, до тех пор, пока СУБД не могут реализовать их напрямую.
Как и в случае с классами сущностей, решение должно основываться на общности использования, стабильности и соблюдении ограничений. Используются ли индивидуальные отношения аналогичным образом? Можем ли мы ожидать дальнейших отношений? Стабильны ли правила, которые соблюдаются отношениями?
15.1 Обобщение нескольких отношений «один ко многим» на одно отношение «многие ко многим»
Имейте в виду возможность обобщения только некоторых отношений «один ко многим» и оставить остальное на месте. Это может быть уместно, если одно или два отношения являются основополагающими для бизнеса, в то время как другие являются “дополнительными”.
15.2 Обобщение нескольких отношений «один ко многим» на одно отношение «один ко многим»
Обобщение нескольких отношений «один ко многим» для формирования единого отношения «многие ко многим» уместно, если отдельные отношения «один ко многим» являются взаимоисключающими, что является более распространенной ситуацией, чем вы могли бы предположить. Можно указать на это с помощью дуги эксклюзивности.
15.3 Обобщение отношений «Один ко многим» и «Многие ко многим»
Обобщение должно быть довольно очевидным, но нужно признать, что если включить в обобщение отношения «один ко многим», потеряются правила, согласно которым только один сотрудник может занимать должность или действовать на должности.
Во многих текстах и статьях, посвященных моделированию данных, основное внимание уделяется дезагрегированию, особенно путем нормализации. Решения об уровне обобщения часто скрываются или отвергаются как “здравый смысл”. Нужно относиться к этому с большим подозрением, поскольку до того, как были формализованы правила нормализации, этот процесс тоже рассматривался как просто вопрос здравого смысла.
Подтипы и супертипы используются для представления разных уровней обобщения классов сущностей. Они облегчают нисходящий подход к разработке и представлению моделей данных и краткую документацию бизнес-правил, касающихся данных. Они поддерживают креативность, позволяя исследовать и сравнивать альтернативные модели данных.
Подтипы и супертипы напрямую не реализуются стандартными реляционными СУБД. Поэтому логические и физические модели данных должны быть свободны от подтипов. Приняв соглашение о том, что подтипы не являются перекрывающимися и исчерпывающими, можно гарантировать, что каждый уровень обобщения является допустимым вариантом реализации.
Конвенция приводит к потере некоторых представительских полномочий, но она широко используется на практике.
- Arif Zainurrohman/Subtypes and Supertypes/ URL- https://medium.com/nerd-for-tech/subtypes-and-supertypes-ef3b6b37c250
- LearnDateModeling/ URL- https://learndatamodeling.com/blog/supertype-and-subtype/
- Bestprog/ URL- https://www.bestprog.net/en/2019/01/27/entity-subtypes-supertype-example-advantages-and-disadvantages-of-using-subtypes-of-entities/