Что такое подзапросы? Если рассматривать кратко, то это выражение представляющее из себя три этапа Select (что ищем) — From (из какой таблицы ищем) — Where ( где ищем)
Коррелированный подзапрос — это один из способов чтения каждой строки в таблице и сравнения значений в каждой строке со связанными данными. Он используется всякий раз, когда подзапрос должен возвращать другой результат или набор результатов для каждой строки-кандидата, рассмотренной основным запросом. Другими словами, вы можете использовать коррелированный подзапрос для ответа на составной вопрос, ответ на который зависит от значения в каждой строке, обрабатываемой родительским оператором.
В настоящее время в различных информационных системах (ИС) используются системы управления базами данных, поддерживающие реляционную модель данных. Здесь для описания и манипулирования данными применяется стандартный язык SQL, который относится к классу непроцедурных языков. SQL-запрос, поступивший на сервер базы, подвергается оптимизации с целью уменьшить время его выполнения. Суть оптимизации состоит в генерации нескольких альтернативных планов реализации запроса и выборе плана с наименьшей стоимостью, которая пропорциональна времени выполнения запроса. В теории реляционных баз данных наибольшее внимание уделяется построению оптимальных планов для класса запросов, включающих операции соединения таблиц или имеющих конструкции, которые можно свести к соединению [1, 2]. В теории по существу не рассматривается важный класс запросов с многоуровневыми вложенными коррелированными подзапросами и операциями агрегирования. В публикациях [3, 4] в основном анализируются запросы с двумя коррелированными подзапросами (внешним и внутренним) и необоснованно утверждается, что для них оптимальным является план с группированием значений атрибута связи. При этом расчет стоимости и сравнение альтернативных планов не выполняются. Это привело к тому, что во многих СУБД (Oracle, DB2 и др.) для реализации запросов из указанного класса используются планы на основе операции группирования. Но анализ показывает, что эти планы являются оптимальными только в некоторой облас- 4 ти изменения параметров запросов и наполнения базы данных. То есть часто для реализации запроса в СУБД выбирается неоптимальный план. Поэтому важной является задача генерации альтернативных планов выполнения запросов с многоуровневыми вложенными коррелированными подзапросами и операциями агрегирования, оценки стоимости планов и построения областей их предпочтительного использования.
Преобразование SQL-запроса с вложенными коррелированными подзапросами и операциями агрегирования.
На рис. 1 приведено описание исследуемого класса запросов.

Рис. 1. Описание исследуемого класса запросов.
Опишем введенные обозначения и дадим ряд пояснений. Ri (i =1,n) – таблица i-го подзапроса, из которой читаются записи в процессе выполнения запроса. Некоторые или все таблицы могут совпадать. A10 – атрибут таблицы R1, который является результатом выполнения запроса (A10 может быть подмножеством атрибутов или операций агрегирования). Ai1 (i =1,n -1) – атрибут i-й таблицы, для которого установлено подусловие поиска Ai1 ti fi+1(Ai+1,2). ti (i =1,n -1) – арифметический оператор сравнения (=, >, >=, < и т.д.). fi (i = 2,n ) – одна из операций агрегирования (MIN, MAX, SUM, COUNT, AVG и др.). Это может быть и арифметическое выражение, куда входят несколько операций агрегирования. Ai2 (i = 2, n ) – атрибут i-й таблицы, являющийся аргументом функции агрегирования fi. Агрегирование значений Ai2 выполняется для тех записей таблицы Ri, которые удовлетворяют условию WHERE i-го вложенного подзапроса. Будем считать, что 1-й вложенный подзапрос – это самый внешний запрос SELECT. Ai3 (i = 1, n -1) – атрибут i-й таблицы, по которому устанавливается соединение с (i+1)-й таблицей (Ri+1) в (i+1)-м подзапросе (поэтому подзапрос является коррелированным). Ai4 (i = 2, n ) – атрибут i-й SELECT A10 FROM R1 WHERE A11 t1 (SELECT f2(A22) FROM R2 WHERE R1.A13=R2.A24 AND A21 t2 (SELECT f3(A32) FROM R3 WHERE R2.A23=R3.A34 AND A31 t3 (SELECT f4(A42) FROM R4 … AND An-1,1 tn-1 (SELECT fn(An2) FROM Rn WHERE Rn-1.An-1,3=Rn.An4 ) …))) 5 таблицы, по которому устанавливается соединение с (i–1)-й таблицей (Ri – 1) в i-м подзапросе. В приведенных выше спецификациях (см. рис. 1) связь между таблицами соседних подзапросов устанавливается посредством равенства атрибутов Ai-1,3 и Ai4. Хотя возможны и более сложные условия.
Приведем пример запроса из рассмотренного класса (рис. 2). 
Рис. 2. Пример запроса с вложенными коррелированными подзапросами и операциями агрегирования.
Этот запрос можно интерпретировать следующим образом: найти сотрудников организации, зарплата которых не меньше средней зарплаты сотрудников соответствующего отдела, в свою очередь, выполнявших максимальное число заказов среди сотрудников управления, куда входит данный отдел. На рис. 3 показан результат частичной трансляции описания запроса (см. рис. 1) в дерево выражений реляционной алгебры. В дальнейшем префиксы Ri и Ri+1 перед атрибутами Ai3 и Ai+1,4 будем опускать, поскольку ясно, что эти атрибуты принадлежат соответственно таблицам Ri и Ri+1. На логическом уровне операции на рис. 3 выполняются при перемещении по дереву снизу вверх. Здесь на каждом i-м уровне вложенности (i =1,n -1) введена операция s без индекса, которая определяет отношение, получаемое после выполнения операции селекции с условием Ai1 ti fi+1(Ai+1,2) над отношением R1 или sAi-1,3=Ai4. Операция sAi-1,3=Ai4 – операция селекции с условием, указанным в качестве индекса, над отношением Ri (i = 2,n ). Операция pA10 – это проекция предыдущего в дереве разбора отношения на атрибут A10, которая определяет результат выполнения исходного запроса. Из-за коррелированности подзапросов физическая реализация плана (см. рис. 3) отличается от логической интерпретации. Действительно, при движении по дереву снизу вверх (логическая интерпретация) невозможно определить результат селекции sAi-1,3=Ai4, так как отношение Ri–1 определяется по дереву выше. Поэтому в процессе физической реализации дерево просматривается сверху вниз. Сначала читаются записи из R1. Для каждой SELECT Номер сотрудника FROM сотрудник R1 WHERE зарплата >= (SELECT AVG(зарплата) FROM сотрудник R2 WHERE R1.номер отдела= R2.номер отдела AND число заказов = (SELECT MAX(число заказов) FROM сотрудник R3 WHERE R2.код управления= R3.код управления )) 6 такой записи определяется отношение sA13=A24 (значение A13 уже определено). Далее для каждой записи из этого отношения определяется отношение sA23=A34 (значение A23 уже определено), и так далее до самого нижнего уровня вложенности. Затем для каждой записи из рассматриваемых отношений sAi-1,3=Ai4 выполняется перемещение снизу вверх, связанное с проверкой условий s (без индекса) и вычислением функций агрегирования fi.
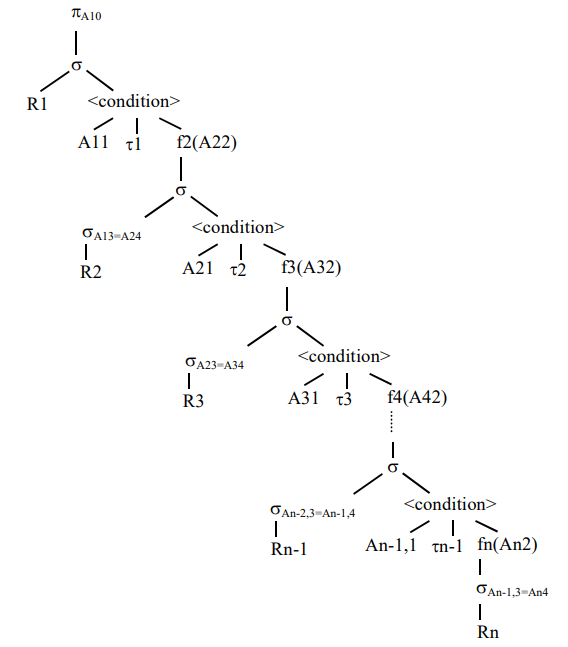
Рис. 3. Результат трансляции исходного запроса.
Далее будет показано, что при некоторых значениях параметров запроса и наполнения базы данных такой процесс выполнения запроса (см. рис. 3) может потребовать достаточно много вычислительных ресурсов. Ниже разрабатывается процедура преобразования плана, представленного на рис. 3.
Для изменения плана необходимо выполнить следующие шаги на каждом уровне вложенности: 1. Селекцию sAi-1,3=Ai4 переместить вверх по дереву за операцию селекции s без индекса, т.е. после ее выполнения (рис. 4).
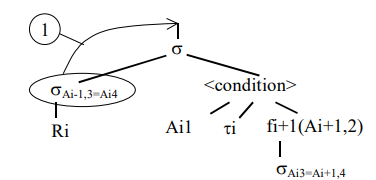
Рис. 4. Перемещение селекции
2. Операцию селекции sAi3=Ai+1,4 переместить за операцию селекции s без индекса. На место перемещенной селекции вставить операцию группирования g(Ai+1,4 ri+1, fi+1(Ai+1,2) qi+1) (рис. 5). Здесь Ai+1,4 – это атрибут, по которому выполняется группирование. Группируемое отношение поступает на вход операции g после выполнения операций, расположенных по дереву ниже. fi+1(Ai+1,2) – операция агрегирования атрибута Ai+1,2, которая выполняется для каждой группы. Идентификаторы ri+1 и qi+1 – псевдонимы значений, указанных слева от них, т.е. Ai+1,4 и fi+1(Ai+1,2) соответственно.
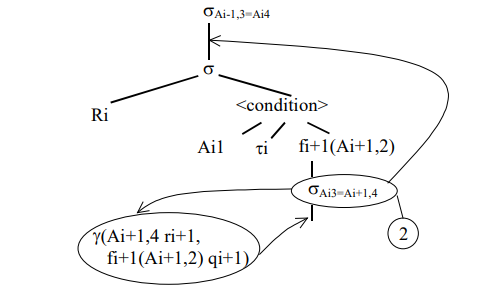
Рис. 5. Перемещение селекции sAi3=Ai+1,4 .
3. Операцию селекции s без индекса и условие заменить на селекцию sAi1 ti qi+1 над декартовым произведением Ri и g (рис. 6).
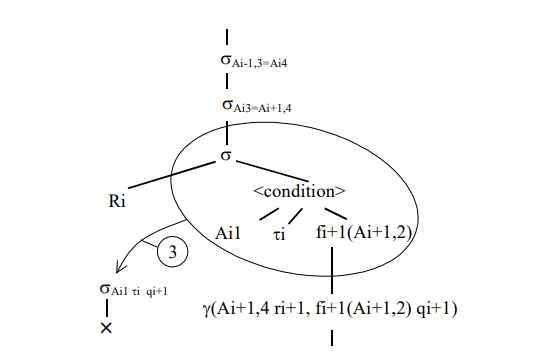
Рис. 6. Замена селекции s без индекса.
4. Каскад селекций sAi3=Ai+1,4 и sAi1 ti qi+1 заменить на одиночную селекцию sAi3=Ai+1,4 Ç Ai1 ti qi+1 (рис. 7).
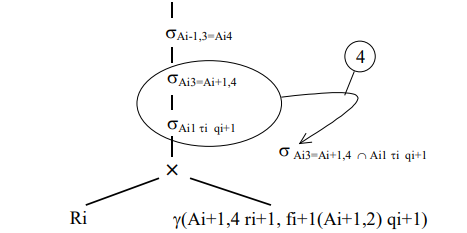
Рис. 7. Замена каскада селекций.
Приведенные выше четыре шага (будем в дальнейшем называть их процедурой 1-4) соответствуют i-му уровню вложенности подзапроса (см. рис. 3). Процедура 1 – 4 является рекурсивной и ее следует выполнить для всех i, начиная с (n – 1) до 1 (селекцию sA03=A14 будем считать пустой). Последовательно применяя процедуру 1 – 4 для каждого уровня вложенности (i меняется от n –1 до 1), план, представленный на рис. 3 (исходный план), преобразуем к дереву, которое изображено на рис. 8 (альтернативный план). Теперь покажем, что преобразования 1 – 4 являются корректными, т.е. после выполнения процесса, представленного на рис. 8, будет получен 9 правильный результат поиска данных.
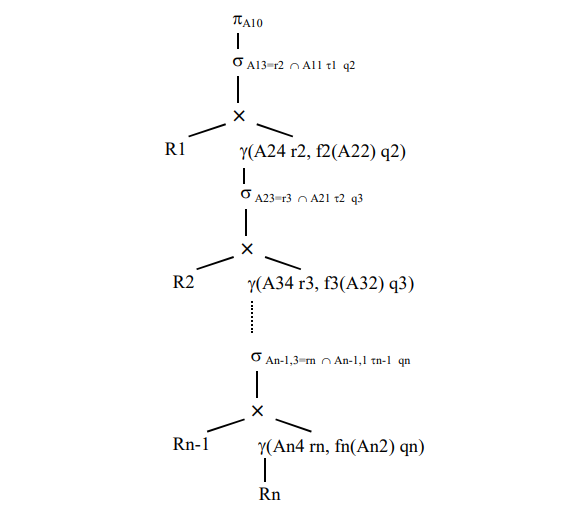
Рис. 8. Альтернативный план выполнения исходного запроса.
Перестановка операций sAi-1,3=Ai4 и s без индекса (см. рис. 4) является корректной в силу закона реляционной алгебры о коммутативности операции селекции. То же можно сказать и об операциях sAi3=Ai+1,4 и s без индекса (см. рис. 5). Только здесь селекция sAi3=Ai+1,4 переносится вверх по дереву за пределы (i+1)-го подзапроса. То есть имеет место отложенная селекция. Чтобы это стало возможным, необходимо в (i+1)-м вложенном подзапросе определить все значения атрибута Ai+1,4, обеспечивающего связь с подзапросом более высокого уровня, и выполнить агрегирование Ai+1,2 для каждого значения Ai+1,4. Это можно реализовать за счет операции группирования g (GROUP BY). Получаемое отношение g (см. рис. 5) позволяет в дальнейшем связать два соседних подзапроса с учетом требуемых условий: Ai3=Ai+1,4 и Ai1 ti fi+1(Ai+1,2). Операция s без индекса с аргументами Ri и (Ai1 ti fi+1(Ai+1,2)) эквивалентна операции селекции sAi1 ti qi+1, выполняемой над декартовым произведением отношений Ri и g (см. рис. 6). Далее каскад селекций sAi3=Ai+1,4 и sAi1 ti qi+1 можно объединить в одиночную селекцию (см. рис. 7) в силу соответствующего 10 закона реляционной алгебры. Итак, доказательство корректности преобразования дерева на рис. 3 в план, представленный на рис. 8, завершено. В работах [3, 4] необоснованно утверждается, что только план на рис. 8 является оптимальным. Ряд СУБД (Oracle, DB2 и др.) этим планом и ограничиваются. В следующих разделах статьи будут определены условия, при которых целесообразно использовать тот или иной план выполнения исходного запроса (рис. 3 или рис. 8). В некоторых СУБД, например Oracle, план на рис. 8 выполняется неэффективно на физическом уровне (здесь соединение sAi3=ri+1 Ç Ai1 ti qi+1 реализуется путем фильтрации всех записей уровня i). Ниже приведены «n» SQL-операторов (рис. 9), совокупность которых соответствует плану на рис. 8.

Рис. 9. Запросы SQL, моделирующие план на рис. 8.
Заключение 1. На основе законов реляционной алгебры разработан метод преобразования исходного плана выполнения запроса с многоуровневыми вложенными коррелированными подзапросами и операциями агрегирования в 14 альтернативный план, что позволяет выбирать план с наименьшим временем реализации в информационных системах. 2. Получены формулы для производящей функции числа обработанных записей и преобразования Лапласа-Стилтьеса времени выполнения запроса для исходного и альтернативного плана, позволяющие вычислять математические ожидания и моменты более высоких порядков. 3. Для исходного и альтернативного плана выполнено сравнение математических ожиданий времени выполнения запроса из определенного подкласса для различных случаев и построены области преимущественного использования этих планов.
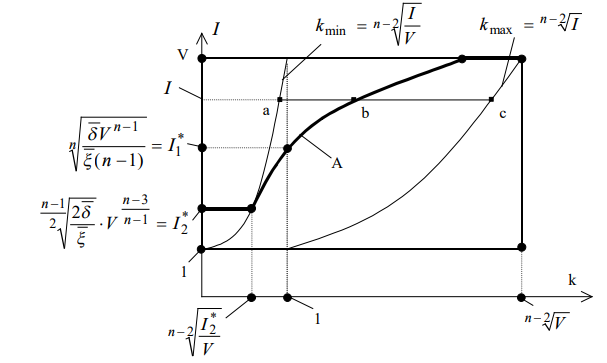
Рис. 10. Области преимущественного использования исходного и альтернативного плана.
ЛИТЕРАТУРА.
- http://www.kuzelenkov.narod.ru/mati/book/progr/progr3.html
- https://studfile.net/preview/7492513/page:6/
- https://translated.turbopages.org/proxy_u/en-ru.ru.879dbd04-63c6f653-19912d1a-74722d776562/https/www.geeksforgeeks.org/sql-correlated-subqueries/
- https://learndb.ru/articles/article/57
- http://www.kodesource.top/sql/subqueries/corelated-subqueries-using-aliases.php