Иерархические базы данных — самая ранняя модель представления сложной структуры данных. Информация в иерархической базе организована по принципу древовидной структуры, в виде отношений «предок-потомок». Каждая запись может иметь не более одной родительской записи и несколько подчиненных. Связи записей реализуются в виде физических указателей с одной записи на другую. Основной недостаток иерархической структуры базы данных — невозможность реализовать отношения «много-ко-многим», а также ситуации, когда запись имеет несколько предков.
Иерархические базы данных. Иерархические базы данных графически могут быть представлены как перевернутое дерево, состоящее из объектов различных уровней. Верхний уровень (корень дерева) занимает один объект, второй — объекты второго уровня и так далее.
Между объектами существуют связи, каждый объект может включать в себя несколько объектов более низкого уровня. Такие объекты находятся в отношении предка (объект, более близкий к корню) к потомку (объект более низкого уровня), при этом объект-предок может не иметь потомков или иметь их несколько, тогда как объект-потомок обязательно имеет только одного предка. Объекты, имеющие общего предка, называются близнецами.
Иерархической базой данных является Каталог папок Windows, с которым можно работать, запустив Проводник. Верхний уровень занимает папка Рабочий стол. На втором уровне находятся папки Мой компьютер, Мои документы, Сетевое окружение и Корзина, которые являются потомками папки Рабочий стол, а между собой является близнецами. В свою очередь, папка Мой компьютер является предком по отношению к папкам третьего уровня -папкам дисков (Диск 3,5(А:), (С:), (D:), (Е:), (F:)) и системным папкам (сканер, bluetooth и.т.д.) — рис. 1.
Организация данных в СУБД иерархического типа определяется в терминах: элемент, агрегат, запись (группа), групповое отношение, база данных.
- А
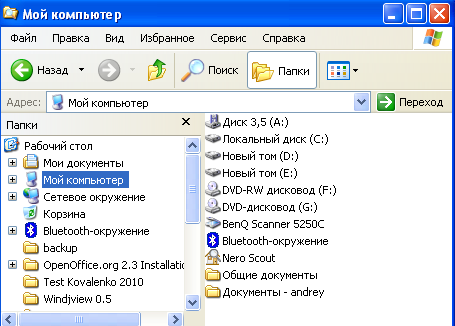
Рисунок 1 Иерархическая база данных Каталог папок Windows
Атрибут (элемент данных) — наименьшая единица структуры данных. Обычно каждому элементу при описании базы данных присваивается уникальное имя. По этому имени к нему обращаются при обработке. Элемент данных также часто называют полем.
- Запись — наименованная совокупность атрибутов. Использование записей позволяет за одно обращение к базе получить некоторую логически связанную совокупность данных. Именно записи изменяются, добавляются и удаляются. Тип записи определяется составом ее атрибутов. Экземпляр записи — конкретная запись с конкретным значением элементов
- Групповое отношение — иерархическое отношение между записями двух типов. Родительская запись (владелец группового отношения) называется исходной записью, а дочерние записи (члены группового отношения) — подчиненными. Иерархическая база данных может хранить только такие древовидные структуры.
Корневая запись каждого дерева обязательно должна содержать ключ с уникальным значением. Ключи некорневых записей должны иметь уникальное значение только в рамках группового отношения. Каждая запись идентифицируется полным сцепленным ключом, под которым понимается совокупность ключей всех записей от корневой по иерархическому пути.
При графическом изображении групповые отношения изображают дугами ориентированного графа, а типы записей — вершинами (диаграмма Бахмана).
Для групповых отношений в иерархической модели обеспечивается автоматический режим включения и фиксированное членство. Это означает, что для запоминания любой некорневой записи в БД должна существовать ее родительская запись.
Пример:
Рассмотрим следующую модель данных предприятия (см. рис.2): предприятие состоит из отделов, в которых работают сотрудники. В каждом отделе может работать несколько сотрудников, но сотрудник не может работать более чем в одном отделе.
Поэтому, для информационной системы управления персоналом необходимо создать групповое отношение, состоящее из родительской записи ОТДЕЛ (НАИМЕНОВАНИЕ_ОТДЕЛА, ЧИСЛО_РАБОТНИКОВ) и дочерней записи СОТРУДНИК (ФАМИЛИЯ, ДОЛЖНОСТЬ, ОКЛАД). Это отношение показано на рис. 4.2 (а) (Для простоты полагается, что имеются только две дочерние записи).
Для автоматизации учета контрактов с заказчиками необходимо создание еще одной иерархической структуры: заказчик — контракты с ним — сотрудники, задействованные в работе над контрактом. Это дерево будет включать записи ЗАКАЗЧИК (НАИМЕНОВАНИЕ_ЗАКАЗЧИКА, АДРЕС), КОНТРАКТ(НОМЕР, ДАТА,СУММА), ИСПОЛНИТЕЛЬ (ФАМИЛИЯ, ДОЛЖНОСТЬ, НАИМЕНОВАНИЕ_ОТДЕЛА) (рис. 4.2 b).
Из этого примера видны недостатки иерархических БД:
Ч
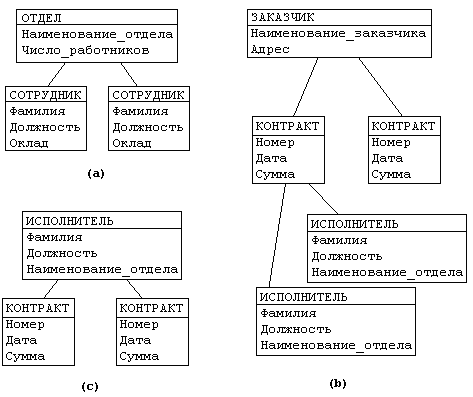
Рисунок 2. Пример иерархической базы данных
Частично дублируется информация между записями СОТРУДНИК и ИСПОЛНИТЕЛЬ (такие записи называют парными), причем в иерархической модели данных не предусмотрена поддержка соответствия между парными записями.
Иерархическая модель реализует отношение между исходной и дочерней записью по схеме 1:N, то есть одной родительской записи может соответствовать любое число дочерних.
Допустим теперь, что исполнитель может принимать участие более чем в одном контракте (т.е. возникает связь типа M:N). В этом случае в базу данных необходимо ввести еще одно групповое отношение, в котором ИСПОЛНИТЕЛЬ будет являться исходной записью, а КОНТРАКТ – дочерней (рис. 4.2 c). Таким образом, мы опять вынуждены дублировать информацию.
Операции над данными, определенные в иерархической модели:
- ДОБАВИТЬ в базу данных новую запись. Для корневой записи обязательно формирование значения ключа.
- ИЗМЕНИТЬ значение данных предварительно извлеченной записи. Ключевые данные не должны подвергаться изменениям.
- УДАЛИТЬ некоторую запись и все подчиненные ей записи.
- ИЗВЛЕЧЬ:
извлечь корневую запись по ключевому значению, допускается также последовательный просмотр корневых записей
извлечь следующую запись (следующая запись извлекается в порядке левостороннего обхода дерева)
В операции ИЗВЛЕЧЬ допускается задание условий выборки (например, извлечь сотрудников с окладом более 10 тысяч руб.)
Как видим, все операции изменения применяются только к одной «текущей» записи (которая предварительно извлечена из базы данных). Такой подход к манипулированию данных получил название «навигационного».
Свойства
— несколько узлов низшего уровня связано только с одним узлом высшего уровня;
— иерархическое дерево имеет только одну вершину (корень), не подчиненный никакой другой вершине;
— каждый узел имеет свое имя (идентификатор);
— узел содержит один или несколько атрибутов, описывающих объект в данном узле;
— доступ к порожденным узлам возможен только через исходный узел.
Достоинства:
— наличие промышленных СУБД;
— простота понимания принципа иерархии;
— обеспечение определенного уровня независимости данных.
Недостатки:
— сложность отображения связей «многие ко многим»;
— иерархия усложняет операции включения новых объектов в базу данных и удаления старых;
— доступ к любому узлу возможен только через корневой.
б) сетевая модель данных
В основу сетевой модели данных положены сетевые структуры.
Отличие сетевой структуры от иерархической: любой элемент в сетевой структуре может быть связан с любым другим элементом (свободная связь между элементами разных уровней).
Сетевая модель имеет те же основные составляющие (узел, уровень, связь).
В сетевой структуре между объектами присутствуют 2 вида взаимосвязей: «один ко многим», «многие к одному».
Недостатки:
— сложность;
— возможная потеря независимости данных при реорганизации базы данных.
в) реляционная модель данных (табличная)
Термин «реляционный» произошел от лат.слова relatio–отношение. Построена на взаимоотношении составляющих ее частей. В простейшем случае она представляет собой двухмерный массив (двухмерную таблицу), а при создании сложных информационных моделей составляет совокупность взаимосвязанных таблиц.
Основное отличие от иерархической и сетевой моделей — отсутствие связей в явном виде.
Свойства модели:
1) каждый элемент таблицы – один элемент данных;
2) все поля в таблице являются однородными, т.е. имеют один тип (числа, текст, дата и т.д.)
3) каждое поле имеет уникальное имя;
4) одинаковые строки в таблице отсутствуют;
5) порядок следования строк произвольный.
Достоинства:
— простота и доступность;
— независимость данных;
— гибкость.
Недостатки:
— имеет более низкую скорость доступа и требует большего объема внешней памяти;
— большое количество таблиц затрудняет понимание структуры данных;
— не всегда предметную область можно представить в виде совокупности таблиц.
Для преодоления недостатков в настоящее время развиваются многомерная и объектно-ориентированная модели.
Если реляционная модель данных состоит из нескольких таблиц, то они связываются ключами.
Язык манипулирования данными в иерархических базах данных
Для доступа к базе данных у пользователя должна быть сформирована специальная среда окружения, поддерживающая в явном виде имеющиеся навигационные операции. Для этого в ней должны храниться:
- шаблоны всех записей логических баз данных, доступных пользователю;
- указатели на текущий экземпляр сегмента данного типа — для всех типов сегментов.
Язык манипулирования данными в иерархической модели поддерживает в явном виде навигационные операции. Эти операции связаны с перемещением указателя, который определяет текущий экземпляр конкретного сегмента.
Все операторы в языке манипулирования данными можно разделить на 3 группы. Первую группу составляют операторы поиска данных.
Операторы поиска данных
Синтаксис:
GET UNIQUE <имя сегмента> WHERE <список поиска>;
список поиска состоит из последовательности условий вида:
<имя сегмента>.<имя поля>ОС <constant или имя другого поля данного сегмента или имя переменной>;
ОС — операция сравнения;
условия могут быть соединены логическими операциями И и ИЛИ { & , ![]() }.
}.
Назначение:
Получить единственное значение.
Пример:
Найти типовую модель стоимостью не более $600, которая существует не менее чем в 10 экземплярах.
GET UNIQUE ТИПОВЫЕ МОДЕЛИ WHERE Типовые модели.Стоимость <= $600 AND Типовые модели.Количество на складе >= 10
Данная команда всегда ищет с начала БД и останавливается, найдя первый экземпляр сегмента, удовлетворяющий условиям поиска.
Синтаксис:
GET NEXT <имя сегмента> WHERE <список аргументов поиска>
Назначение:
Получить следующий экземпляр сегмента для тех же условий.
Пример:
Напечатать полный список заказов стоимостью не менее $500.
GET UNIQUE ИНДИВИДУАЛЬНЫЕ МОДЕЛИ
WHERE Индивидуальные модели.Стоимость >= $500
WHILE NOT FAIL (пока не конец поиска) DO
PRINT № заказа, Стоимость, Количество
GET NEXT ИНДИВИДУАЛЬНЫЕ МОДЕЛИ
END
Синтаксис:
GET NEXT <имя сегмента> WITHIN PARENT [ where <дополн.условия>]
Назначение:
Получить следующий для того же исходного.
Пример:
Получить перечень винчестеров, имеющихся на складе номер 1, в количестве не менее 10 с объемом 10 Гбайт.
GET UNIQUE СКЛАД WHERE Склад.Номер = 1
GET NEXT ИЗДЕЛИЕ WITHIN PARENT
WHERE Изделие.Наименование = «Винчестер»
GET NEXT ХАРАКТЕРИСТИКИ WITHIN PARENT
WHERE ХАРАКТЕРИСТИКИ.Параметр = 10 AND
ХАРАКТЕРИСТИКИ.Единицы Измерения = Гб AND
ХАРАКТЕРИСТИКИ.Величина > 10
WHILE NOT FAIL (пока поиск не завершен) DO
GET NEXT WITHIN PARENT
end
Операторы поиска данных с возможностью модификации
- Найти и удержать единственный экземпляр сегмента. Эта операция подобна первой операции поиска GET UNIQUE, единственным отличием этой операции является то, что после выполнения этой операции над найденным экземпляром сегмента допустимы операции модификации (изменения) данных.
Синтаксис:
GET HOLD UNIQUE <имя сегмента>
WHERE <список поиска>
- Найти и удержать следующий с теми же условиями поиска. Аналогично операции 4 эта операция дублирует вторую операции поиска GET NEXT с возможностью выполнения последующей модификации данных.
Синтаксис:
GET HOLD NEXT [WHERE дополнительные условия>]
- Получить и удержать следующий для того же родителя. Эта операция является аналогом операции поиска 3, но разрешает выполнение операций модификации данных после себя.
Синтаксис:
GET HOLD NEXT WITHIN PARENT [ where <дополн.условия>]
- Удалить
Это первая из трех операций модификации.
Синтаксис:
DELETE
Эта команда не имеет параметров. Почему? Потому что операции модификации действуют на экземпляр сегмента, найденный командами поиска с удержанием. А он всегда единственный текущий найденный и удерживаемый для модификации экземпляр конкретного сегмента. Поэтому при выполнении команды удаления будет удален именно этот экземпляр сегмента.
- Обновить
Синтаксис:
UPDATE
Как же происходит обновление, если мы и в этой команде не задаем никаких параметров. СУБД берет данные из рабочей области пользователя, где в шаблонах записей соответствующих внутренних переменных находятся значения полей каждого сегмента внешней модели, с которой работает данный пользователь. Именно этими значениями и обновляется текущий экземпляр сегмента. Значит, перед тем как выполнить операции модификации UPDATE, необходимо присвоить соответствующим переменным новые значения.
Ввести новый экземпляр сегмента.
INSERT <имя сегмента>
Эта команда позволяет ввести новый экземпляр сегмента, имя которого определено в параметре команды. Если мы вводим данные в сегмент, который является подчиненным некоторому родительскому экземпляру сегмента, то он будет внесен в БД и физически подключен к тому экземпляру родительского сегмента, который в данный момент является текущим.
Как видим, набор операций поиска и манипулирования данными в иерархической БД невелик, но он вполне достаточен для получения доступа к любому экземпляру любого сегмента БД. Однако следует отметить, что способ доступа, который применяется в данной модели, связан с последовательным перемещением от одного экземпляра сегмента к другому. Такой способ напоминает движение летательного аппарата или корабля по заданным координатам и называется навигационным.
Список литературы
- Грофф, Дж. Р. SQL: Полный справочник / Дж Р. Грофф, П. Н. Вайнберг, Э. Дж. Оппель. – 3-е изд. – М.: Вильямс, 2019. – 960 с.
- Дейт, К. Дж. Введение в системы баз данных / К. Дж. Дейт. – 8-изд. – М.: Вильямс, 2020 – 1328 с.
- Латыпова, Р. Р. Базы данных. Курс лекций / Р.Р. Латыпова. — Москва: Высшая школа, 2019. — 177 c.
- Комплекснозначные и гиперкомплексные системы в задачах обработки многомерных сигналов / Я.А. Фурман и др. — М.: ФИЗМАТЛИТ, 2018. — 456 c.
- Илюшечкин, В. М. Основы использования и проектирования баз данных. Учебник / В.М. Илюшечкин. — М.: Юрайт, 2021. — 214 c